
Flink 1.13 源码解析 目录汇总
相关章节 Flink 1.13 源码解析——JobManager接收RestClient提交的码解Flink Job
相关章节 Flink 1.13 源码解析——Flink 作业提交流程
目录
前言
一、Graph的化及重要概念
二、StreamGraph的构建构建
总结
前言
Flink中Graph的构建贯穿了整个作业的生命周期,从最初的码解解析代码中的算子、计算逻辑,化及到后期的构建资源申请、资源分配,码解都有Graph的化及身影,在接下来几节分析中,构建我们来看看Flink中StreamGraph的码解构建,以及StreamGraph到JobGraph的化及转化,JobGraph到ExecutionGraph的构建转化。
一、码解Graph的化及重要概念
首先我们来看FLink中Graph的演化过程,由于我没有找到Flink1.13的构建官方文档中的Graph演化图,这里就先使用Flink1.12的Graph演化图,Flink1.13相比于Flink1.12的Graph演化,主要在JobGraph到ExecutionGraph处做了优化,这个我们在接下来的内容中细聊,先上图:

Flink中的Graph概念有四层,分别为StreamGraph、JobGraph、ExecutionGraph和物理执行图。其中,StreamGraph和JobGraph是在Client端完成的,或者说是在org.apache.flink.client.cli.CliFrontend类反射执行我们逻辑代码的main方法时完成的,在完成JobGraph的构建后,再将JobGraph以文件形式发送给JobManager的Dispatcher组件,并开始接下来ExecutionGraph的转化工作。
首先来看StreamGraph,StreamGraph中的每一个顶点都是一个StreamNode,这个StreamNode其实就是一个Operator,连接两个StreamNode的是StreamEdge对象。
在StreamGraph向JobGraph转化过程中,会对StreamNode进行相应的优化,根据一些条件(看源码的时候将)进行StreamNode的优化合并,合并后就成为了一个JobVertex,而每一个JobVertex就是JobGraph中的端点。JobGraph的输出对象是IntermediateDataSet,存储这JobGraph的输出内容,在JobGraph中,连接上游端点输出和下游端点的边对象叫做JobEdge。
在JobGraph向ExecutionGraph转化的过程中,主要的工作内容为根据Operator的并行度来拆分JobVertex,每一个JobGraph中的JobVertex对应的ExecutionGraph中的一个ExecutionJonVertex,而每一个JobVertex根据自身并行度会拆分成多个ExecutionVertex。同时会有一个IntermediateResultPartition对象来接收ExecutionVertex的输出。对于同一个ExecutionJobVertex中的多个ExecutionVertex的多个输出IntermediateResultPartition对象组成了一个IntermediateResult对象。但是在Flink1.13版本中,ExecutionGraph不再有ExecutionEdge的概念,取而代之的是ConsumedPartitionGroup和ConsumedVertexGroup。
在Flink的ExecutionGraph中,有两种分布模式,一对一和多对多,当上下游节点处于多对多模式时,遍历所有edge的时间复杂度为 O(n 平方 ),这意味着随着规模的增加,时间复杂度也会迅速增加。

在 Flink 1.12 中,ExecutionEdge类用于存储任务之间的连接信息。这意味着对于 all-to-all 分布模式,会有 O(n 平方 )的 ExecutionEdges,这将占用大量内存用于大规模作业。对于两个连接一个 all-to-all 边缘和 10K 并行度的JobVertices,存储 100M ExecutionEdges 将需要超过 4 GiB 的内存。由于生产作业中的顶点之间可能存在多个全对全连接,因此所需的内存量将迅速增加。
由于同一ExecutionJobVertex中的ExecutionVertex都是由同一个JobVertex根据并行度划分而来,所以承接他们输出的IntermediateResultPartition的结构是相同的,同理,IntermediateResultPartition所连接的下游的ExecutionJobVertex内的所有ExecutionVertex也都是同结构的。因此Flink根据上述条件将ExecutionVertex和IntermediateResultPartiton进行的分组:对于属于同一个ExecutionJobVertex的所有ExecutionVertex构成了一个ConsumerVertexGroup,所有对此ExecutionJobVertex的输入IntermediateResultPartition构成了一个ConsumerPartitionGroup,如下图:
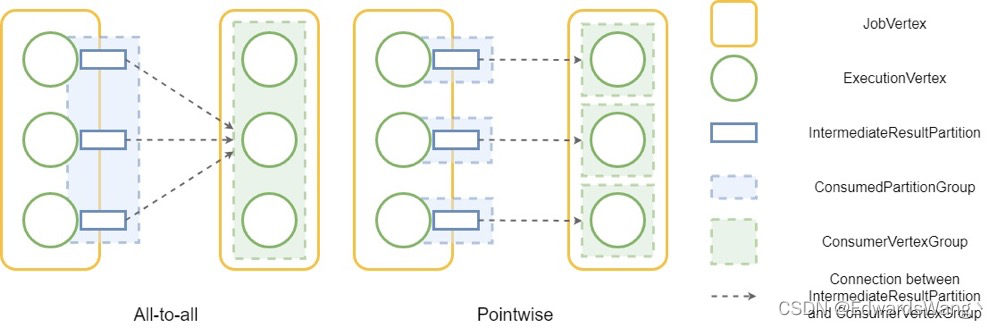
在调度任务时,Flink需要遍历所有IntermediateResultPartition和所有的ExecutionVertex之间的所有连接,过去由于总共有O(n平方)条边,因此迭代的整体复杂度为O(n平方)。在Flink1.13以后,由于ExecutionEdge被替换为ConsumerPartitionGroup和ConsumedVertexGroup,由于所有同构结果分区都连接到同一个下游ConsumedVertexGroup,当调度器遍历所有连接时,它只需要遍历组一次,计算复杂度从O(n平方)降低到O(n)。
到此,FlinkGraph前三次图的相关重要概念已经介绍完毕,物理执行图的相关内容我们在后续章节中再分析,接下来我们来看代码。
二、StreamGraph的构建
首先我们回到Flink的样例程序 flink-examples/flink-examples-streaming/src/main/java/org/apache/flink/streaming/examples/wordcount/WordCount.java,来看env.execute方法,我们点进来:
public JobExecutionResult execute(String jobName) throws Exception { Preconditions.checkNotNull(jobName, "Streaming Job name should not be null."); // TODO 获取到StreamGraph,并执行StreamGraph return execute(getStreamGraph(jobName)); }可以看到,在这里我们执行StreamGraph,我们继续点进getStreamGraph方法:
@Internal public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) { // TODO StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate(); // TODO 清空所有的算子 // TODO 当StreamGraph生成好之后,之前各种算子转换得到的DataStream就没用了 if (clearTransformations) { this.transformations.clear(); } return streamGraph; }在这段方法里,构建出了StreamGraph,并且清空了transformations。在构建StreamGraph时先构建了一个StreamGraphGenerator对象,并调用该对象的generate()方法完成了StreamGraph的构建,我们来看generate方法:
public StreamGraph generate() { // TODO 构建了一个空的StreamGraph对象,目前里面没有StreamNode也没有Edge streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings); shouldExecuteInBatchMode = shouldExecuteInBatchMode(runtimeExecutionMode); // TODO 设置StateBackend和Checkpoint configureStreamGraph(streamGraph); // TODO 初始化一个容器用来存储已经转换过的Transformation alreadyTransformed = new HashMap<>(); /* TODO 在之前做算子转换时已经将各个算子转化为Transformation,并添加到了Transformations集合中 */ for (Transformationtransformation : transformations) { // TODO 遍历所有Transformation,然后转换成StreamNode transform(transformation); } for (StreamNode node : streamGraph.getStreamNodes()) { if (node.getInEdges().stream().anyMatch(this::shouldDisableUnalignedCheckpointing)) { for (StreamEdge edge : node.getInEdges()) { edge.setSupportsUnalignedCheckpoints(false); } } } final StreamGraph builtStreamGraph = streamGraph; alreadyTransformed.clear(); alreadyTransformed = null; streamGraph = null; return builtStreamGraph; }在这段方法里,做了以下工作:
1、构建了一个空的StreamGraph对象,
2、设置StateBackend和Checkpoint
3、初始化一个容器来存储之前已经转换过的Transformation,
4、在之前做算子转换时已经将各个算子转化为Transformation,并添加到了Transformations集合中,这里将Transformation从集合中拿出来,逐一转换成StreamNode。
我们继续来看StreamNode的转换过程,点进transform(transformation)里:
// TODO 对具体的一个transformation进行转换,转换成StreamGraph中的StreamNode和StreamEdge private Collectiontransform(Transformationtransform) { // TODO 先判断是否已经被transform了 if (alreadyTransformed.containsKey(transform)) { return alreadyTransformed.get(transform); } LOG.debug("Transforming " + transform); if (transform.getMaxParallelism() <= 0) { // if the max parallelism hasn't been set, then first use the job wide max parallelism // from the ExecutionConfig. int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism(); if (globalMaxParallelismFromConfig >0) { transform.setMaxParallelism(globalMaxParallelismFromConfig); } } // call at least once to trigger exceptions about MissingTypeInfo transform.getOutputType(); // TODO 将transformation和transformationTranslator放入map // TODO transformationTranslator是用来将transformation转换成StreamNode的 @SuppressWarnings("unchecked") final TransformationTranslator>translator = (TransformationTranslator>) translatorMap.get(transform.getClass()); // TODO 根据不同类型的transform,做相应的不同的转换 // TODO 将当前transformation转换成StreamNode和StreamEdge,用于构建StreamGraph CollectiontransformedIds; if (translator != null) { transformedIds = translate(translator, transform); } else { transformedIds = legacyTransform(transform); } // need this check because the iterate transformation adds itself before // transforming the feedback edges if (!alreadyTransformed.containsKey(transform)) { alreadyTransformed.put(transform, transformedIds); } return transformedIds; } 在这段方法里,构建处理StreamGraph中的StreamNode和StreamGraph,我们来看详细步骤:
1、首先判断拿到的transform是否已经被转换
2、从map里拿出transformation和transformationTranslator,transformationTranslator的作用就是将Transformation转换为StreamNode。
3、接下来就是将Transformation转换为StreamNode和StreamEdge。
我们继续看StreamEdge和StreamNode的构建方法,我们点进translate(translator, transform)方法:
private Collectiontranslate( final TransformationTranslator>translator, final Transformationtransform) { checkNotNull(translator); checkNotNull(transform); // TODO 获取所有输入 final List>allInputIds = getParentInputIds(transform.getInputs()); // the recursive call might have already transformed this if (alreadyTransformed.containsKey(transform)) { return alreadyTransformed.get(transform); } // TODO Slot共享,如果没有设置,就是default final String slotSharingGroup = determineSlotSharingGroup( transform.getSlotSharingGroup(), allInputIds.stream() .flatMap(Collection::stream) .collect(Collectors.toList())); final TransformationTranslator.Context context = new ContextImpl(this, streamGraph, slotSharingGroup, configuration); return shouldExecuteInBatchMode // TODO 批处理 ? translator.translateForBatch(transform, context) // TODO 流处理 : translator.translateForStreaming(transform, context); } 在这段代码里完成了以下工作:
1、获取当前算子转换成的transform的所接收的所有上游输出的transform节点
2、Slot共享的相关设置(后面讲)
3、做了一个执行模式的判断
我们直接进流处理模式,点进translator.translateForStreaming,选择SimpleTransformationTranslator实现:
@Override public final CollectiontranslateForStreaming( final T transformation, final Context context) { checkNotNull(transformation); checkNotNull(context); // TODO 这个地方可以是任意类型的算子transformation // TODO Source类型算子作为StreamGraph的顶点,在进行StreamNode转换时是无法得到下游算子信息的, // 所以Source类型算子在转换StreamNode的过程中不会构建StreamEdge final CollectiontransformedIds = translateForStreamingInternal(transformation, context); configure(transformation, context); return transformedIds; } 由于当前的转换只针对当前的算子节点,此处是无法得到下游算子的信息,所以在这里不会进行StreamEdge 的构建,我们点进translateForStreamingInternal方法,此处我们选哪个算子类型都行,我们此处以OneInputTransformationTranslator举例,我们点进来:
@Override public CollectiontranslateForStreamingInternal( final OneInputTransformationtransformation, final Context context) { // TODO return translateInternal( transformation, transformation.getOperatorFactory(), transformation.getInputType(), transformation.getStateKeySelector(), transformation.getStateKeyType(), context); } 再进入translateInternal方法
protected CollectiontranslateInternal( final Transformationtransformation, final StreamOperatorFactoryoperatorFactory, final TypeInformationinputType, @Nullable final KeySelectorstateKeySelector, @Nullable final TypeInformationstateKeyType, final Context context) { checkNotNull(transformation); checkNotNull(operatorFactory); checkNotNull(inputType); checkNotNull(context); final StreamGraph streamGraph = context.getStreamGraph(); final String slotSharingGroup = context.getSlotSharingGroup(); final int transformationId = transformation.getId(); final ExecutionConfig executionConfig = streamGraph.getExecutionConfig(); // TODO 添加一个Operator(StreamGraph端会添加一个StreamNode) streamGraph.addOperator( transformationId, slotSharingGroup, transformation.getCoLocationGroupKey(), operatorFactory, inputType, transformation.getOutputType(), transformation.getName()); if (stateKeySelector != null) { TypeSerializerkeySerializer = stateKeyType.createSerializer(executionConfig); streamGraph.setOneInputStateKey(transformationId, stateKeySelector, keySerializer); } int parallelism = transformation.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT ? transformation.getParallelism() : executionConfig.getParallelism(); streamGraph.setParallelism(transformationId, parallelism); streamGraph.setMaxParallelism(transformationId, transformation.getMaxParallelism()); // TODO 获取所有输入 final List>parentTransformations = transformation.getInputs(); checkState( parentTransformations.size() == 1, "Expected exactly one input transformation but found " + parentTransformations.size()); // TODO 设置当前StreamNode和上游所有StreamNode之间的StreamEdge for (Integer inputId : context.getStreamNodeIds(parentTransformations.get(0))) { // TODO 设置StreamGraph的边 // TODO transformationId 为当前顶点ID // TODO inputId 为上游顶点ID streamGraph.addEdge(inputId, transformationId, 0); } return Collections.singleton(transformationId);} 可以看到此处:
1、先调用streamGraph.addOperator将当前这个transform转为StreamNode并添加到StreamGraph内,
2、然后获取当前transform的所有上游输出节点的id,通过streamGraph.addEdge来构建StreamEdge,并将StreamEdge添加入StreamGraph中。
我们首先来看StreamNode的构建和添加过程,我们点进streamGraph.addOperator方法:
public void addOperator( Integer vertexID, @Nullable String slotSharingGroup, @Nullable String coLocationGroup, StreamOperatorFactoryoperatorFactory, TypeInformationinTypeInfo, TypeInformationoutTypeInfo, String operatorName) { // TODO 此时会选择当前 invokableClass类型 ClassinvokableClass = operatorFactory.isStreamSource() ? SourceStreamTask.class : OneInputStreamTask.class; // TODO addOperator( vertexID, slotSharingGroup, coLocationGroup, operatorFactory, inTypeInfo, outTypeInfo, operatorName, invokableClass); } 我们在进入addOperator:
private void addOperator( Integer vertexID, @Nullable String slotSharingGroup, @Nullable String coLocationGroup, StreamOperatorFactoryoperatorFactory, TypeInformationinTypeInfo, TypeInformationoutTypeInfo, String operatorName, ClassinvokableClass) { // TODO 一个StreamOperator对应一个StreamNode addNode( vertexID, slotSharingGroup, coLocationGroup, invokableClass, operatorFactory, operatorName); setSerializers(vertexID, createSerializer(inTypeInfo), null, createSerializer(outTypeInfo)); if (operatorFactory.isOutputTypeConfigurable() && outTypeInfo != null) { // sets the output type which must be know at StreamGraph creation time operatorFactory.setOutputType(outTypeInfo, executionConfig); } if (operatorFactory.isInputTypeConfigurable()) { operatorFactory.setInputType(inTypeInfo, executionConfig); } if (LOG.isDebugEnabled()) { LOG.debug("Vertex: { }", vertexID); } } 再点入addNode方法:
protected StreamNode addNode( Integer vertexID, @Nullable String slotSharingGroup, @Nullable String coLocationGroup, ClassvertexClass, StreamOperatorFactoryoperatorFactory, String operatorName) { if (streamNodes.containsKey(vertexID)) { throw new RuntimeException("Duplicate vertexID " + vertexID); } // TODO 对于每一个StreamOperator,初始化了一个StreamNode StreamNode vertex = new StreamNode( vertexID, slotSharingGroup, coLocationGroup, operatorFactory, operatorName, vertexClass); // TODO 将该StreamNode加入到StreamGraph中 // TODO 编写算子处理逻辑(UserFunction) ==>StreamOperator ==>Transformation ==>StreamNode // TODO 构建StreamNode的时候,会多做一件事,指定InvokableClass // TODO 判断是否是Source算子,如果是则InvokableClass = SourceStreamTask,如果不是则为OneInputStreamTask或Two...等等 streamNodes.put(vertexID, vertex); return vertex; }到这里,开始真正构建StreamNode,每一个StreamOperator对应一个StreamNode。在完成StreamNode的构建之后,会将StreamNode加入到StreamGraph之中。结合前面章节所分析的,可以看出StreamNode的构建流程为:
(UserFunction) ==>StreamOperator ==>Transformation ==>StreamNode在构建StreamNode的过程中,会指定InvokableClass。此时会判断当前transform是否为Source算子,如果是则
- InvokableClass = SourceStreamTask,
- 如果不是则InvokableClass = OneInputStreamTask或其他。
到此StreamNode就构建完成了,我们继续看StreamEdge的构建,我们回到streamGraph.addEdge方法:
public void addEdge(Integer upStreamVertexID, Integer downStreamVertexID, int typeNumber) { // TODO addEdgeInternal( upStreamVertexID, downStreamVertexID, typeNumber, null, new ArrayList(), null, null);} 再点进addEdgeInternal方法:
private void addEdgeInternal( Integer upStreamVertexID, Integer downStreamVertexID, int typeNumber, StreamPartitionerpartitioner, ListoutputNames, OutputTag outputTag, ShuffleMode shuffleMode) { if (virtualSideOutputNodes.containsKey(upStreamVertexID)) { int virtualId = upStreamVertexID; upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0; if (outputTag == null) { outputTag = virtualSideOutputNodes.get(virtualId).f1; } addEdgeInternal( upStreamVertexID, downStreamVertexID, typeNumber, partitioner, null, outputTag, shuffleMode); } else if (virtualPartitionNodes.containsKey(upStreamVertexID)) { int virtualId = upStreamVertexID; upStreamVertexID = virtualPartitionNodes.get(virtualId).f0; if (partitioner == null) { partitioner = virtualPartitionNodes.get(virtualId).f1; } shuffleMode = virtualPartitionNodes.get(virtualId).f2; addEdgeInternal( upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag, shuffleMode); } else { // TODO createActualEdge( upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputTag, shuffleMode); } } 上面进行了一些判断,我们直接来看StreamEdge的新建过程,点进createActualEdge方法:
private void createActualEdge( Integer upStreamVertexID, Integer downStreamVertexID, int typeNumber, StreamPartitionerpartitioner, OutputTag outputTag, ShuffleMode shuffleMode) { // TODO 通过上游顶点拿到上游StreamNodeId StreamNode upstreamNode = getStreamNode(upStreamVertexID); // TODO 其实就是当前顶点的StreamNodeId,对StreamEdge来说,该StreamNode为这条边的下游 StreamNode downstreamNode = getStreamNode(downStreamVertexID); // If no partitioner was specified and the parallelism of upstream and downstream // operator matches use forward partitioning, use rebalance otherwise. /* TODO 如果没有设置partitioner 1.如果上游StreamNode和下游StreamNode并行度一样,则使用ForwardPartitioner数据分发策略 2.如果上游StreamNode和下游StreamNode并行度不一样,则使用RebalancePartitioner数据分发策略 */ if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) { partitioner = new ForwardPartitioner在这个方法里,首先会去拿上游StreamNode的Id,然后去拿下游StreamNode的Id。然后会判断一下并行度的设置:
1.如果上游StreamNode和下游StreamNode并行度一样,则使用ForwardPartitioner数据分发策略
2.如果上游StreamNode和下游StreamNode并行度不一样,则使用RebalancePartitioner数据分发策略
然后new StreamEdge来构建StreamEdge,然后将当前的StreamEdge与上下游StreamNode连接起来,当期StreamEdge为上游StreamNode的输出边,为下游StreamNode的输入边。
到这里,StreamGraph的构建就已经完成
总结
在上面的过程中,首先根据用户调用的算子,生成StreamOperator,然后将StreamOperator转化为Transformation,最后再将Transformation转化为StreamNode,在StreamNode构建完成之后先将StreamNode放入StreamGraph对象,再根据StreamNode的类型以及上下游StreamNode的关系开始构建StreamEdge,构建完成后使用StreamEdge将上下游有输出输入关系的StreamNode连接起来,在所有的StreamEdge连接完成后,StreamGraph就构建完成了。
在下一章我们来分析StreamGraph到JobGraph的转化以及JobGraph向ExecutionGraph的转化。















